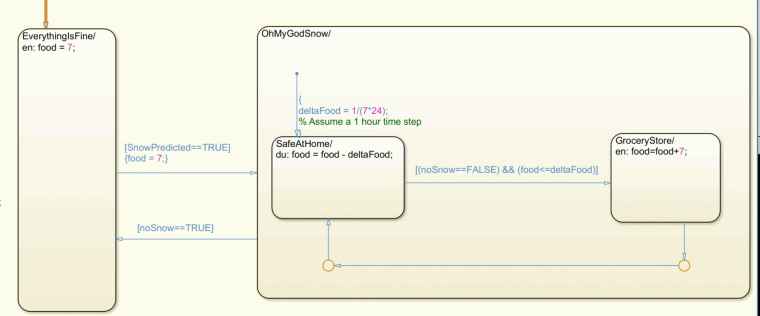
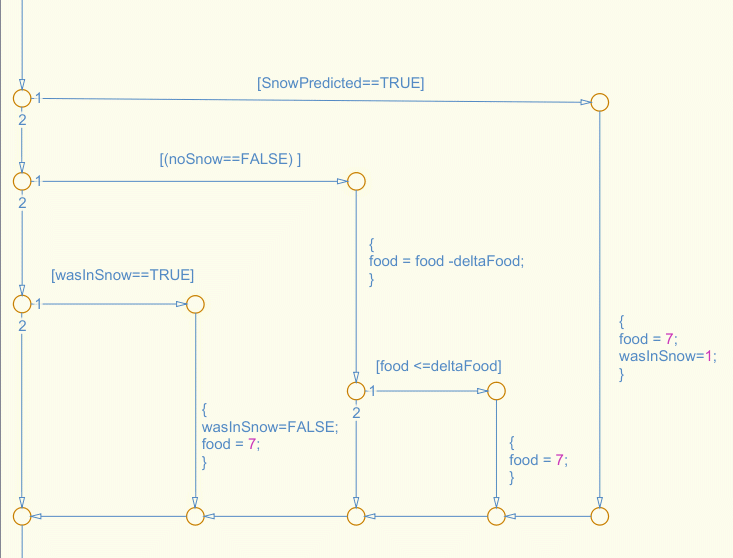
Early in my career one of my mentors made the statement
“If we understand the system we can model it.
If we can model it we can make predictions.
If we can make predictions we can make improvements”
In the past 20+ years, I have not heard a better statement of the driving ethos behind Model-Based Design.
If we understand the system, we can model it:(What we need to do): when the system is understood, it can be described mathematically. This could be a derived first principal model or a statistical model; the important thing is that the confidence in the model fidelity is understood.
If we can model, we can make predictions:(What we can do): once the model is known it can be used. The use of the model can be in the design of a controller, predicting a rainfall or embedded within a system to allow the system to respond with better insight.
If we can make predictions, we can make improvements:(Why we do it): this last part is the heart of Model-Based Design. Once we can make accurate predictions we can use that information to improve what we are doing.
Model and equation…
Models build on a foundation of equations to provide a dynamic, time variant representation of the real-world phenomenon. Moreover those equations are working as part of a system; you leverage models when you move into complex systems with multiple interdependent equations. Within the Model-Based Design world, we most often think of these systems as closed loop system. Similar examples can be seen in the social sciences, in biology and chemistry.
to provide a dynamic, time variant representation of the real-world phenomenon. Moreover those equations are working as part of a system; you leverage models when you move into complex systems with multiple interdependent equations. Within the Model-Based Design world, we most often think of these systems as closed loop system. Similar examples can be seen in the social sciences, in biology and chemistry.
Understanding from a sewage treatment plant…
Coming from an aerospace background, and starting my working career out in the automotive industry the general nature of models sunk in during one of my earliest consulting engagement; helping a customer model a sewage treatment plant to determine optimal processing steps against a set of formal requirements.
- Requirements
- The plant may not discharge more than N% of water in untreated state
- The plant’s physical size cannot exceed Y square miles
- …
- Objectives
- Minimize the total processing cost of sewage treatment (weight: ω)
- Minimize the total processing time of sewage (weight: λ)
- Maximize the production of energy from bio-gas (weight: Φ)
- ….
- Variants of inputs
- Sewage inflow base rate has +/- 15% flow rate change
- Extreme storm conditions can increase flow rate by 50%
- ….
The final system model included bio-chemical reactions, fluid dynamic models, statistical “flush rates” and many other domains that I have now forgotten. The final model was not able to answer all of the questions that the engineers had, however, it did allow them to design a plant with significantly lower untreated discharge rates and lower sewage processing costs. This was possible because of the models. This was the project that showed me just how expensive Model-Based Design is.


 The simulation is used during the early stage of development to analyze the model to determine if the functional behavior of the model. The developer performs elaborates the model until the behavior functionality matches the requirements. This is verified through simulation. Once the model meets the requirements the functionality can be “locked down” through the use of formal tests; again using simulation.
The simulation is used during the early stage of development to analyze the model to determine if the functional behavior of the model. The developer performs elaborates the model until the behavior functionality matches the requirements. This is verified through simulation. Once the model meets the requirements the functionality can be “locked down” through the use of formal tests; again using simulation. a clean sheet there will be existing software components that need to be integrated with those created by the Model-Based Design process. There are three types of integration
a clean sheet there will be existing software components that need to be integrated with those created by the Model-Based Design process. There are three types of integration The primary objectives during this phase are
The primary objectives during this phase are